Get yourself introduced with Monkey! No, its not a monkey from the zoo but a model for generating in-depht details from a graphic visual. This training efficient approach create pertinent corelation between scenes and objects.
Zhang Li, Biao Yang, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu, Xiang Bai from Huazhong University of Science and Technology and Kingsoft involved in this study and they named the model as Monkey.
In the wide-ranging field of image-to-text generation, dealing with complex images and detail settings remains a great challenge. Existing models underperforms due to limited input resolution and inadequate trainings.
To make these models efficient, extensive trainings were required which utilize maximum resources in the form of memory and space. Generating brief and one sentence caption was not enough for the complex images.
Various LLMs showed notable competency in visual-text related tasks. The latest model Monkey was designed with existing vision encoder to enhance input resolution, without training the model from scratch. Multi-layered caption generation technique was proposed for extensive information generation, showing relevant connections. The models create strong bonding between objects in the image and generate the detail captions without skipping any object and its relation with the whole image.
How Monkey Works!!
Monkey enhances the resolution of input image and Multi layered method was proposed to generate details which help to gather maximum information from the given input images. The generated caption specifically focus on creating the association among the objects in the image. This model is helpful in the field of General Visual Question and Answering, Image Captioning and Document-oriented VQA.

The above image shows the abstract view of the model. An image is given as an input and the generated output showed the detailed information with the relationship between the objects. The working of Monkey from the image show-cases a high-level understanding of visuals, excelling in identifying subtle elements such as contextual objects. It particularly excels in understanding small text and navigating complex image compositions, skillfully inferring context form minimal visual cues. The code of this model is available on GitHub. The research paper is also open source and available on Arxiv.
Architecture of Monkey

To generate good quality association among image and text, Monkey’s contribution is significant. The above image (a) showing a comprehensive procedure in a pipeline diagram. The example is showing step-by-step detection of main objects which is further refined by showing the relation between the objects. Furthermore, the percentage is showing how accurate image has relation with the generated text using pre-trained model BLIP2. Whereas, same image incomplete and inaccurate captions was generated with the same input image, when CC3M dataset was used.
The above image (b) is showing that an input image is divided into four patches to enhance the image resolution. Each image processed using separate visual encoder, simultaneously. All the data is transferred to a shared Resampler to effectively compact the data, showing the textual output.
Dataset used for Monkey
Monkey uses the pretrained existing vision encoder that is vit-BitHuge with 2b parameters which enhances the resolution of input image. Existing datasets like Laion, COYO and CC3M were used for model pretraining. However, for complex images these datasets were unable to create bonding between images and generated captions. To reduce this gap BLIP2 Li, PPOCR, GRIT, SAM and ChatGPT were used for concise information.
Monkey was compared with several other LLMs, including GPT4V, LLaVA1.5, mPLUG-Owl and Qwen-VL-Chat. Comparison proved that this model performed incredible in image captioning by focusing on textual information and capturing minute details, considering improved input resolution.
Conclusion
This model enhances the resolution of input images without pre-training from the scratch. Multi-level description method generates text with all the necessary information, showing excellent result on different benchmarks.
References
Similar Posts
-
LayoutPrompter: Automatic-layout generation using with Large Language Models

-
LOOGLE: Long-Context perceive extended phrases

-
Mirror: An Ubiquitous Model for Information Extraction related Tasks
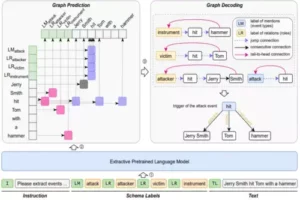
-
TopicGPT: In-context Topic Generation using LLM (Large Language Model)

-
Microsoft Interns Revolutionize AI: LEMA the Error-Driven Learning

-
INT8 quantization: Large Language Models (LLMs) effects on CPU inference
